- ¿Qué es el robots.txt?
- Ejemplo de archivo robots.txt:
- Herramientas para crear y probar archivos robots.txt
- Mejores prácticas para optimizar el robots.txt
- Relación entre el robots.txt y el sitemap
- ¿Por qué Google no obedece el Robots.txt y Rastrea páginas bloqueadas?
- Para que se usa el archivo robots.txt de forma avanzada.
- Recomendaciones para el Robots.txt para distintos CMS
- Consideraciones sobre el Robots.txt
- Actualización sobre el Robots.txt
¿Qué es el robots.txt?
El robots.txt es un archivo de texto plano que se coloca en la raíz de un sitio web. Su función principal es proporcionar instrucciones a los robots de los motores de búsqueda (como Googlebot) sobre qué partes del sitio pueden rastrear y cuáles no.
Es un protocolo de exclusión que permite a los webmasters controlar el acceso de los robots a su sitio.
¿Qué hace el archivo robots.txt?
- Indica qué páginas pueden ser rastreadas: Especifica las URL que los robots pueden visitar y analizar.
- Bloquea secciones del sitio: Impide que los robots accedan a ciertas áreas, como directorios internos, archivos temporales o contenido duplicado.
- Mejora la eficiencia del rastreo: Al limitar el alcance del rastreo, se reduce la carga en el servidor y se optimiza el uso de los recursos.
- Protege la privacidad: Permite ocultar contenido que no se desea que sea indexado por los motores de búsqueda.
Para que sirve el robots.txt en SEO
- Optimiza en crawl budget de nuestra web: Al indicar qué páginas son importantes y cuáles no, ayudas a los motores de búsqueda a optimizar su tiempo de rastreo, centrándose en el contenido más relevante.
- No mostrar contenido no deseado: Puedes evitar que se indexen páginas de prueba, duplicadas, de administración o cualquier otro contenido que no quieras que aparezca en los resultados de búsqueda.
- Proteger recursos: Impides que los robots accedan a archivos grandes o que requieran muchos recursos, como imágenes de alta resolución o vídeos, lo que puede mejorar la velocidad de carga de tu sitio.
- Organizar el rastreo: Puedes guiar a los robots hacia las páginas más importantes de tu sitio web, facilitando su indexación.
- Bloqueas páginas duplicadas: un caso bastante frecuente para el que podemos usar el robots.txt es el de evitar que Google llegue a contenido duplicado, si desde el primer momento así se lo indicamos.
¿Cómo debería ser el archivo robots.txt?
Un archivo robots.txt debe ser un archivo de texto plano, sin formato, y se guarda con la extensión .txt.
Debe estar ubicado en la raíz de tu dominio (ej: dobleo.com/robots.txt).
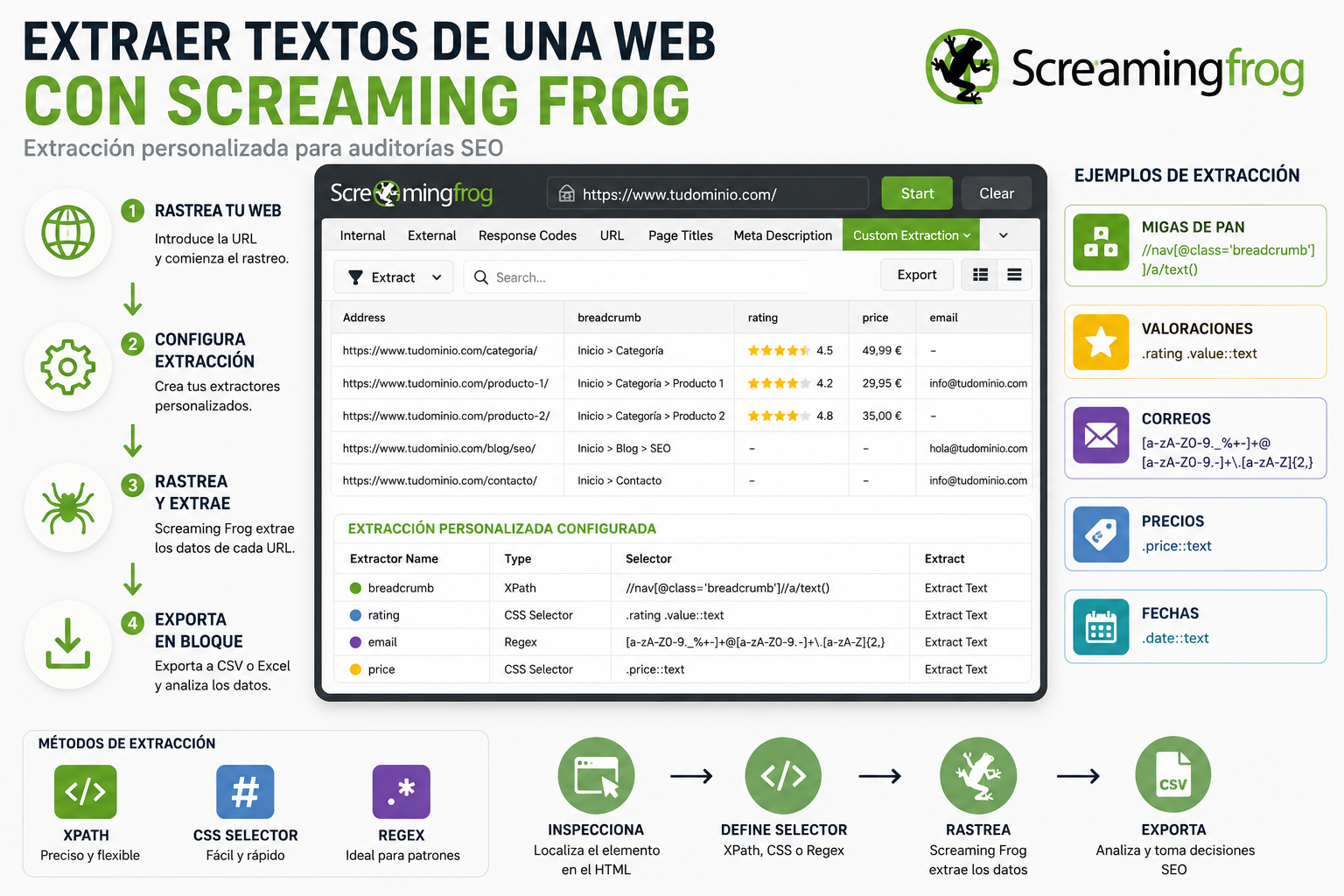
¿Qué se puede indicar en el archivo robots.txt? ¿Cómo redactar el Robots.txt?
Para poder redactar un Robots.txt de forma correcta, es importante entender la sintaxis del Robots.txt. Pongamos como ejemplo el Robots.txt de Semrush:
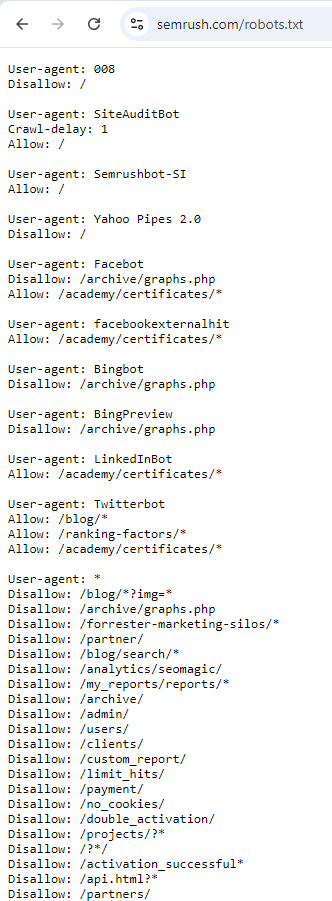
Fuente: https://www.semrush.com/robots.txt
Vemos que los espacios entre una regla y el user-agent van separando indicaciones especificas para cada uno de esos user-agents.
Veamos que significa cada una de los elementos del Robots.txt:
- User-agent: Especifica el robot al que se dirigen las instrucciones (ej: Googlebot). En el ejemplo de Semrush, vemos los siguientes user-agents: 008; SiteAuditBot; Semrushbot-SI; Yahoo Pipes 2.0; Facebot; facebookexternalhit; Bingbot; BingPreview; LinkedInBot; Twitterbot y finalmente * (que son reglas que aplica a todos los robots.)
Luego tenemos 3 indicaciones claves:
- Disallow: Indica las URLs o directorios a los que el robot no debe acceder.
- Allow: Indica las URLs o directorios a los que el robot sí puede acceder.
- Crawl-delay: Aunque en el Robots.txt de Semrush, no se observa, es un comando que puede usarse para darle un respiro al servidor e indicarle al bot que haga una breve pausa al momento de analizar y leer el Robots.txt. Esta indicación, es ideal para no sobrecargar el servidor y genere problemas que ralenticen la web.
Esta indicación del Crawl-delay Google no la interpreta, pero otros robots si que pueden interpretarla.
- Sitemap: Por regla general, también incluimos en el Robots.txt ya que proporciona la URL del sitemap de tu sitio.
- Comentarios en el Robots.txt: Como en todo código, podemos usar las // para incluir comentarios que ayuden a otras personas que tengan que gestionar o editar el código del Robots.txt.
¿Qué se puede bloquear en el robots.txt?
- Directorios internos: Carpetas que contienen archivos temporales, copias de seguridad o contenido no público.
- Archivos de sistema: Archivos como .htaccess, index.php, etc.
- Páginas de búsqueda: Páginas con parámetros de búsqueda (ej: ?s=).
- Contenido duplicado: Páginas con contenido idéntico o muy similar.
- Páginas de administración: Áreas restringidas del sitio web.
¿Qué no se puede hacer con en el robots.txt?
El archivo robots.txt solo puede impedir que los robots accedan a una página, no puede impedir que sea indexada si un robot la encuentra a través de otro enlace. Además, el archivo robots.txt no influye directamente en el posicionamiento de una página en los resultados de búsqueda.
Ejemplo de archivo robots.txt:
User-agent: *
Disallow: /admin/
Disallow: /cgi-bin/
Disallow: /images/
Disallow: /includes/
Sitemap: https://dobleo.com/sitemap.xml
En este ejemplo:
Se bloquea el acceso a los directorios /admin/, /cgi-bin/, /images/ e /includes/ y además, se indica la ubicación del sitemap.
¿Cómo enviar el archivo robots.txt a Google?
En realidad, no es necesario «enviar» el archivo robots.txt a Google. Los robots de Google exploran constantemente la web y, si encuentran un archivo robots.txt en la raíz de un sitio, lo leerán automáticamente y seguirán las instrucciones que contiene.
En el caso que necesites forzar la lectura de las reglas del robots.txt y quieres que Google lo tenga, puedes usar la herramienta de Robots.txt de Google Search Control:

Herramientas para crear y probar archivos robots.txt
Puedes crear un archivo robots.txt usando cualquier editor de texto plano, como el Bloc de notas de Windows o TextEdit en macOS. Simplemente abre un nuevo documento, escribe las instrucciones y guarda el archivo como «robots.txt» en la raíz de tu sitio. Sin embargo, aunque puedes crear un archivo robots.txt con cualquier editor de texto, existen herramientas que facilitan este proceso y te ayudan a evitar errores:
- Generadores de robots.txt: Estas herramientas te ofrecen plantillas predefinidas y te guían paso a paso en la creación de tu archivo. Algunos ejemplos son:
- GoogieHost: Ofrece un generador gratuito con opciones básicas y avanzadas.
- Yoast SEO (para WordPress): Este plugin popular incluye un generador de robots.txt que se adapta a las necesidades de tu sitio WordPress.
- Probadores de robots.txt: Estas herramientas te permiten verificar si tu archivo robots.txt funciona correctamente y si hay algún error en la sintaxis o en las reglas que has definido. Algunos ejemplos son:
- Herramienta de inspección de URL de Google Search Console: Te permite ver cómo Google interpreta tu archivo robots.txt para una URL específica.
- Probadores de robots.txt online: Existen numerosas herramientas en línea gratuitas que te permiten introducir tu archivo robots.txt y analizarlo.
Informe de Robots.Txt en Google Search Console (GSC)
Esta herramienta no es mas que una forma de verificar si Google ha visto o no el sitemap y te permite ver las indicaciones que tiene cacheada y la última fecha en la que entró.
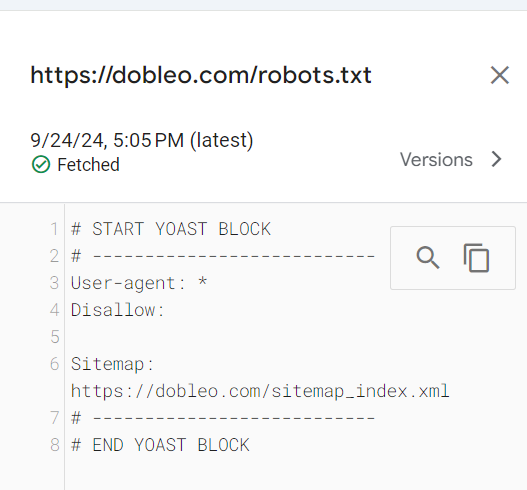
Mejores prácticas para optimizar el robots.txt
Aquí dejamos algunas recomendaciones para que tu Robots.txt sea fácil de gestionar y de entender por todos los robots:
- Mantenlo simple: Evita reglas demasiado difíciles, complejas o redundantes. Mientras mas conciso sea el archivo, será más fácil de entender y mantener.
- Prioriza las páginas importantes: Permite que los robots accedan fácilmente a las páginas que quieres que se indexen.
- Bloquea contenido no deseado: Evita que se indexen páginas de prueba, duplicadas o de baja calidad.
- Utiliza el sitemap: Combina el robots.txt con un sitemap XML para proporcionar a los motores de búsqueda una visión completa de tu sitio. De hecho, este punto requiere de otro post mas especifico, porque es necesario no entrar en conflictos y contradicciones entre las indicaciones que damos en el Robots.txt y el Sitemap.xml.
- Prueba y monitorea: Utiliza herramientas de prueba para verificar que tu archivo funciona correctamente y monitorea regularmente el rendimiento de tu sitio en los resultados de búsqueda.
- Sé específico: En lugar de bloquear directorios enteros, intenta bloquear solo las páginas específicas que no quieres que se indexen, así evitas problemas de rastreo.
- Comenta tu código: Añade comentarios a tu archivo robots.txt para explicar las razones de cada regla y facilitar su comprensión en el futuro. Por lo general vienen acompañado de #
Relación entre el robots.txt y el sitemap
El archivo robots.txt y el sitemap cumplen funciones complementarias:
- Robots.txt: Indica qué partes del sitio puede ser rastreado.
- Sitemap: Proporciona un mapa de tu sitio para que los robots puedan encontrar más fácilmente las páginas importantes.
Es importante tener ambos archivos para optimizar el rastreo y la indexación de tu sitio, sin generar conflictos ni contradicciones entre ambos documentos, ya que esto llevará a que hayan páginas que no queremos se posiciones, indexadas o viceversa y afectar el Crawl Budget.
¿Por qué Google no obedece el Robots.txt y Rastrea páginas bloqueadas?
Esto aunque muchos digan que ocurre, no es cierto.
Para Google es prácticamente mandato divino lo que esté indicado en el Robots.txt, sin embargo, deja muy claro que el robots.txt no es la mejor manera de evitar que una página se indexe, ya que para eso, recomienda el uso de no index.
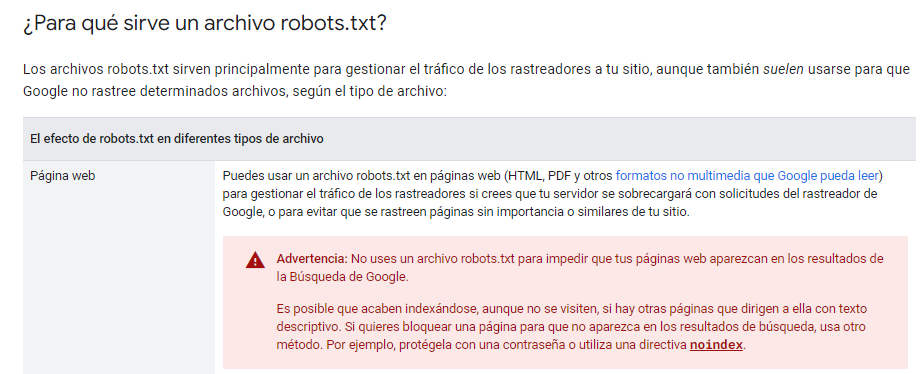
Fuente: https://developers.google.com/search/docs/crawling-indexing/robots/intro
Veamos algunas razones por las que Google podría entrar y rastrear páginas bloqueadas en tu Robots.txt:
Esta mal escrito el Robots.txt
Muchos robots.txt en nuestra experiencia SEO, vienen mal redactados y es porque no se entiende la forma en la que Google puede leer dicho documento.
- Google lee siempre desde el principio de la ruta, por lo que si queremos bloquear: /personal/documentos/privados no podemos usar la siguiente indicación:
Disallow: /documentos/privados
Sino que tendremos que usar:
Disallow: /personal/documentos/privados o Disallow: /*/documentos/privados
Declaración incorrecta de la home
En otras ocasiones, hemos encontrado robots.txt que no usan el primer / en la declaración, esto puede afectar el rastreo (aunque Google si no lo ve lo pone él). En todo caso, mejor poner la / al principio de la regla.
Muchas reglas para muchos user agents
Esto puede complicar la lectura del robots.txt, ya que, si tienes diferentes reglas para diferentes user-agents, lo mejor es repetir las reglas para cada uno de los user-agent dando así las indicaciones de cada uno, por ejemplo:
User-agent: Googlebot
Disallow: /categoria1/
Disallow: /categoria2/
User-agent: Googlebot-Image
Disallow: /videos.html
User-agent: DuckandGo
Disallow: /privados/*
En este ejemplo, estamos dando indicaciones a cada bot, y no estámos relacionando las indicaciones, es decir, Google Bot no puede entrar a /categoria1 ni a /categoria2 y Googlebot-Image solo tiene prohibida la entrada a /videos, por lo tanto, Google Bot si puede entrar a videos y Googlebot-Image si puede entrar a /categoria1 y /categoria2; y por último, DuckandGo puede entrar a todos lados, menos a la carpeta de /privados/
Es importante entender que los user-agents son únicos y no se combinan las indicaciones que damos en el Robots.txt.
Fallas en el Servidor
Si ocurren fallas en el servidor, justo cuando el bot entra a leer nuestro robots.txt y no puede entender las indicaciones que ahí le damos, entonces puede darse el caso de que entre a alguna de las páginas que teníamos bloqueadas, sin embargo, Google intentará nuevamente entrar al Robots.txt y al entender la indicación dejará de rastrear dicha página.
Si por ejemplo, cuando Google entra a nuestra web y quiere entrar al Robots.txt y se encuentra con:
- Status code 200: El Google bot entra sin problemas al Robots.txt y obedece las reglas ahí plasmadas.
- Status code 300: Aquí el bot va a la página a la que ha sido redirigido sin problemas y lee el sitemap como si fuera la ruta original sin problemas.
- Status code 40X: Aquí el bot aterriza en una página vacía, sin reglas, por lo tanto, hará lo que mejor le parezca, entrará a todas las páginas independientemente de tu estrategia de rastreo.
- Status code 50X: Aquí pueden ocurrir varias cosas. Si robots.txt reporta un error 50X de forma continua, después de 30dias el bot de Google usará la última copia de robots.txt almacenada en caché y si ésta no está disponible, Google supone que no hay restricciones de rastreo.
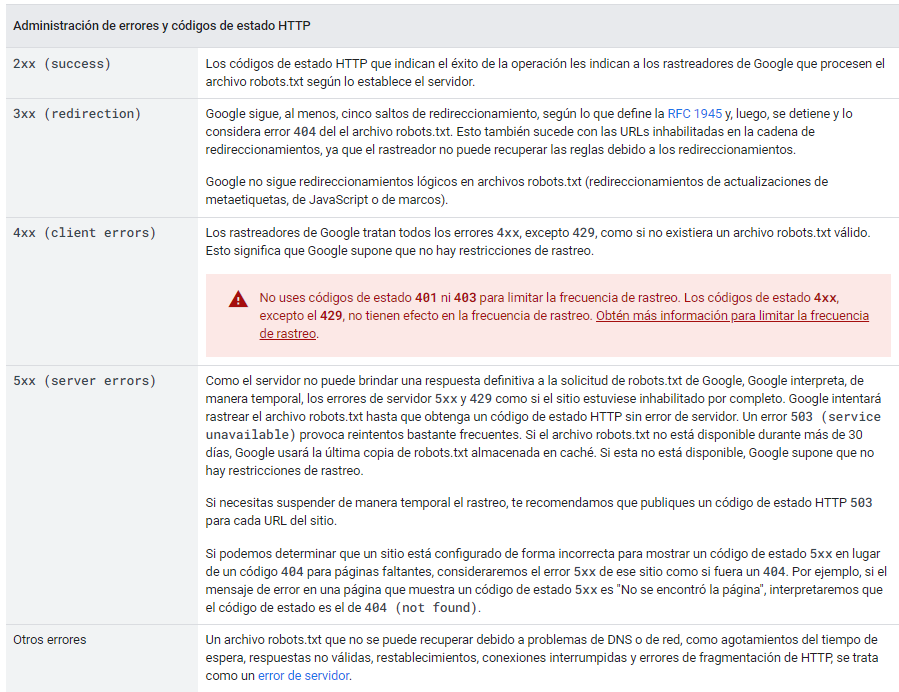
Fuente: https://developers.google.com/search/docs/crawling-indexing/robots/robots_txt?hl=es-419#http-status-codes
Rastreo no es Indexación
Algo que no nos cansamos de repetir los SEOs, es que no hay indexación sin rastreo pero si puede haber rastreo sin indexación, el detalle está en que el rastreo no necesariamente viene desde el Robots.txt.
Cuando Google decide indexar y mostrar en las SERP una página bloqueada en el robots.txt, es porque ha visto la URL en algún otro lado o porque ya estaba indexada.
Por lo tanto, en este caso, no es que «Google indexa sin entrar«; sino que «si que ha entrado por otra vía, y por eso la ha indexado«
La URL que queremos Bloquear tiene Backlinks
Lo comentado anteriormente, si por alguna razón Google identifica enlaces de calidad hacia alguna página, puede darse el caso de que la indexe, incluso sin rastrearla. Estos casos son curiosos y poco frecuentes, pero Google podría indexarla incluso sin verla si considera que esos enlaces son indicadores suficientes de que el contenido es de calidad, aunque Google no pueda rastrearla.
Estas páginas no alcanzarán buenos rankings, porque al final Google no ha podido rastrearla.
Frecuencia de Rastreo y Cambios en el Robots.txt
Aquí hablamos que Google cachea las indicaciones del robots.txt 24h. Si Google lee nuestro robots.txt a las 9am, y a las 10am hacemos cambios en nuestra web, si Google vuelve a las 10pm se quedará con la indicación vista en el robots.txt y verá o no verá dicha página; pero si en el cambio de las 10am, cambiamos el robots.txt y ahora la indicación es otra, igualmente se quedará con lo que tiene cacheado, haciendo que rastree una página que a las 10am hemos decidido que no rastreara.
Para evitar este tipo de cosas, es importante pedirle nuevamente a Google que rastree nuestro sitemap a través de GSC:
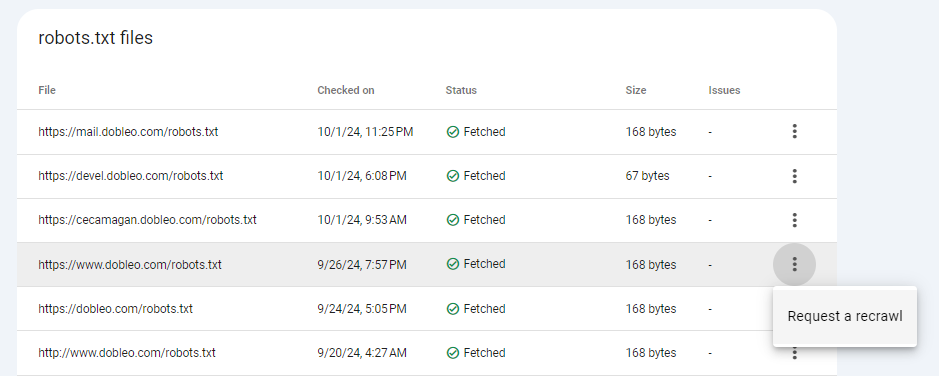
Clicar en REQUEST A RECRAWL
Para que se usa el archivo robots.txt de forma avanzada.
- Gestión de contenido duplicado: Puedes utilizar el robots.txt para bloquear versiones duplicadas de una página, como las versiones para móviles.
- A/B testing: Si estás realizando pruebas A/B, puedes bloquear temporalmente las versiones que no están listas para ser indexadas.
- Protección de contenido premium: Puedes restringir el acceso a contenido de pago o suscriptores mediante el archivo robots.txt.
- Bloqueo de bots maliciosos: Aunque el robots.txt no es una solución completa para proteger tu sitio de bots maliciosos, puede ayudar a reducir el tráfico no deseado.
- Optimización para diferentes motores de búsqueda: Puedes personalizar las reglas para diferentes motores de búsqueda, si es necesario.
Recomendaciones para el Robots.txt para distintos CMS
Es importante destacar que cada CMS es totalmente distinto, además, restricciones adicionales pueden necesitarse según corresponda, por ello, aquí damos algunas recomendaciones que podrían usarse según cada tipo de CMS:

Robots.txt para WordPress
Aunque cada caso puede ser diferente, es importante bloquear aquellas páginas o archivos que no queremos rastree, esto podemos hacerlo con un robots.txt como el siguiente:
Versión mas básica del Robots.txt para WordPress:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://dobleo.com/sitemap_index.xml
Por otro lado, si quisiéramos ser mas restrictivos:
Sitemap: http://example.org/sitemap.xml
User-Agent: *
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-admin/
Disallow: /trackback/
Disallow: /?s=
Disallow: /search
Disallow: /archives/
Disallow: /index.php
Disallow: /*?
Disallow: /*.php$
Disallow: /*.inc$
Disallow: */trackback/ Disallow: /page/
Disallow: /tag/
Disallow: /category/
# No rastrear copias de seguridad
Disallow: /*.git$
Disallow: /*.sql$
Disallow: /*.tgz$
Disallow: /*.gz$
Disallow: /*.tar$
Disallow: /*.svn$
Disallow: /*.bz2$
Disallow: /*.log$
# No rastrear enlaces de WooCommerce
User-agent: *
Disallow: /*add-to-cart=*
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
Robots.txt para Shopify
Si en tu caso, usas Shopify las directrices recomendadas pasan por:
User-agent: *
Disallow: /a/downloads/-/*
Disallow: /admin
Disallow: /cart
Disallow: /orders
Disallow: /checkout
Disallow: /8203042875/checkouts
Disallow: /8203042875/orders
Disallow: /carts
Disallow: /account
Disallow: /collections/*sort_by*
Disallow: /*/collections/*sort_by*
Disallow: /collections/*+*
Disallow: /collections/*%2B*
Disallow: /collections/*%2b*
Disallow: /*/collections/*+*
Disallow: /*/collections/*%2B*
Disallow: /*/collections/*%2b*
Disallow: /blogs/*+*
Disallow: /blogs/*%2B*
Disallow: /blogs/*%2b*
Disallow: /*/blogs/*+*
Disallow: /*/blogs/*%2B*
Disallow: /*/blogs/*%2b*
Disallow: /*?*oseid=*
Disallow: /*preview_theme_id*
Disallow: /*preview_script_id*
Disallow: /policies/
Disallow: /*/*?*ls=*&ls=*
Disallow: /*/*?*ls%3D*%3Fls%3D*
Disallow: /*/*?*ls%3d*%3fls%3d*
Disallow: /search
Disallow: /apple-app-site-association
# El bot de Google Ads, ignora el robots.txt a no ser que especificamente se lo indiques.
User-agent: adsbot-google
Disallow: /checkout
Disallow: /carts
Disallow: /orders
Disallow: /8203042875/checkouts
Disallow: /8203042875/orders
Disallow: /*?*oseid=*
Disallow: /*preview_theme_id*
Disallow: /*preview_script_id*
User-agent: AhrefsSiteAudit
Crawl-delay: 10
Disallow: /a/downloads/-/*
Disallow: /admin
Disallow: /cart
Disallow: /orders
Disallow: /checkout
Disallow: /8203042875/checkouts
Disallow: /8203042875/orders
Disallow: /cartsRobots.txt para Drupal
Aunque puede variar de versión a versión, en Drupal podríamos seguir alguna de estas restricciones o indicaciones:
User-agent: *
# Directorios
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /profiles/
Disallow: /scripts/
Disallow: /themes/
# Archivos
Disallow: /CHANGELOG.txt
Disallow: /cron.php
Disallow: /INSTALL.mysql.txt
Disallow: /INSTALL.pgsql.txt
Disallow: /INSTALL.sqlite.txt
Disallow: /install.php
Disallow: /INSTALL.txt
Disallow: /LICENSE.txt
Disallow: /MAINTAINERS.txt
Disallow: /update.php
Disallow: /UPGRADE.txt
Disallow: /xmlrpc.php
# Rutas (URLs exactas)
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /filter/tips/
Disallow: /user/logout/
Disallow: /node/add/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: /user/login/
# Rutas (URLs no exactas)
Disallow: /?q=admin/
Disallow: /?q=comment/reply/
Disallow: /?q=filter/tips/
Disallow: /?q=user/logout/
Disallow: /?q=node/add/
Disallow: /?q=search/
Disallow: /?q=user/password/
Disallow: /?q=user/register/
Disallow: /?q=user/login/
Disallow: /?q=search/
# Registrando acceso a algunos parámetros y a algunas rutas adicionales.
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: /*?solrsort*
Disallow: /*&solrsort*
# Restringiendo rutas de perfil y usuarios.
Disallow: /profile
Disallow: /profile/*
Disallow: /?q=profile
Disallow: /?q=profile/*
# Restringiendo URLs de agregadores
Disallow: /aggregator/*
# Restringiendo a proyectos o buscador de proyectos.
Disallow: /project/issues/search
Disallow: /project/issues/search/*
Disallow: /project/issues/*/search
# Restringiendo a exportar libros.
Disallow: /book/export/*
# Restringiendo a registro de proyectos.
Disallow: /project/issues/subscribe-mail/*
# Restringiendo acceso a URLs con parámetros.
Disallow: /user/login?destination=*
Disallow: /user/register?destination=*
Disallow: /user?destination=*
# Restringiendo acceso a información de usuarios.
Disallow: /user/*/track
Disallow: /user/*/track?page=*
Robots.txt para Joomla
En el caso de Joomla, se recomienda usar las siguientes indicaciones:
User-agent: * Disallow: /administrator/ Disallow: /api/ Disallow: /bin/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /layouts/ Disallow: /libraries/ Disallow: /logs/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/
Consideraciones sobre el Robots.txt
Consideraciones Generales sobre el Robots.txt
- No es una barrera infranqueable: Aunque el robots.txt indica a los motores de búsqueda qué partes de tu sitio pueden rastrear, no es una garantía de que una página no sea indexada. Si un robot encuentra un enlace a una página bloqueada, podría indexarla de todos modos.
- Complementa el sitemap: El robots.txt y el sitemap trabajan en conjunto. El primero indica qué se puede rastrear, mientras que el segundo proporciona un mapa detallado de tu sitio.
- Actualízalo regularmente: A medida que tu sitio evoluciona, es esencial actualizar el robots.txt para reflejar los cambios.
- Sé específico: En lugar de bloquear directorios enteros, intenta bloquear solo las páginas específicas que no quieres que se indexen.
- Comenta tu código: Añade comentarios a tu archivo robots.txt para explicar las razones de cada regla y facilitar su comprensión en el futuro.
- Consideraciones Técnicas
- Sintaxis: Asegúrate de que la sintaxis de tu archivo sea correcta. Un error tipográfico o una coma en el lugar equivocado puede invalidar todo el archivo.
- Mayúsculas y minúsculas: Las directivas son sensibles a las mayúsculas y minúsculas. Por ejemplo, «User-agent» es diferente de «user-agent».
- Códigos de estado: Los robots de búsqueda pueden seguir enlaces a páginas bloqueadas por robots.txt y recibir un código de estado 403 (Prohibido). Esto puede ser interpretado como un error por parte de los motores de búsqueda.
- Directivas avanzadas: Existen directivas más avanzadas como Crawl-delay, Request-rate, y Noindex que te permiten controlar con mayor precisión el rastreo de tu sitio. Utilízalas con precaución y solo si es necesario.
- No abuses del archivo robots.txt: Bloquear demasiadas páginas puede dificultar la indexación de tu sitio.
- Verifica tu archivo robots.txt: Utiliza herramientas como el «Herramienta de inspección de URL» de Google Search Console para comprobar si tu archivo robots.txt funciona correctamente.
- Mantén tu archivo robots.txt actualizado: A medida que tu sitio evoluciona, es posible que debas modificar el archivo robots.txt para reflejar los cambios.
Consideraciones de SEO sobre el Robots.txt
- Presupuesto de rastreo: Al bloquear secciones de tu sitio, estás limitando el presupuesto de rastreo que los motores de búsqueda dedican a tu sitio. Asegúrate de que las páginas más importantes tengan prioridad.
- Canibalización de palabras clave: Si tienes páginas muy similares y bloqueas una de ellas, podrías estar causando canibalización de palabras clave.
- Experiencia de usuario: Al bloquear secciones importantes de tu sitio, podrías estar perjudicando la experiencia del usuario.
Consideraciones Específicas sobre el Robots.txt
- CMS: Si utilizas un CMS, es posible que tenga opciones integradas para gestionar el archivo robots.txt, por ejemplo, Yoast.
- Sitios web dinámicos: Los sitios web dinámicos con muchas URL pueden requerir un archivo robots.txt más complejo.
- Sitios web multi-idioma: Si tienes un sitio web en varios idiomas, debes tener cuidado de no bloquear accidentalmente contenido en un idioma específico.
Casos Especiales sobre el Robots.txt
- Bloqueo de bots maliciosos: Aunque el robots.txt puede ayudar a reducir el tráfico de bots maliciosos, no es una solución completa.
- A/B testing: Si estás realizando pruebas A/B, puedes utilizar el robots.txt para bloquear temporalmente las versiones que no están listas para ser indexadas.
- Contenido premium: Puedes restringir el acceso a contenido de pago o suscriptores mediante el archivo robots.txt.
Actualización sobre el Robots.txt
En octubre del 2024 Google ha actualizado el manual relacionado sobre el robots.txrt, especialmente donde habla de las sintaxis que el robots.txt de Google entiende.
Google admite los siguientes campos:
user-agent: identifica al rastreador al que se aplican las reglas.allow: ruta de URL que se puede rastrear.disallow: ruta de URL que no se puede rastrear.sitemap: URL completa de un sitemap.
Y además, aclara que no entiende la indicación crawl-delay.

Mas información aquí
Quizás te gusten los siguientes posts:
10 aplicaciones fotográficas para el verano – Marketing Online. SEO
Entre el Amor y el Odio. La Fusión del Arte y la Tecnología
jQuery Mobile Framework – Marketing Online. SEO
Espero que les sea útil, y ya sabes, si te gustó… guarda comenta y comparte que quizás a alguien le pueda ayudar.
Por Alexis Petit – COO de dobleO Agencia de Marketing.