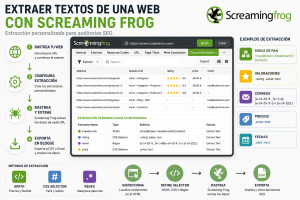
Cómo extraer textos de una web con Screaming Frog

Uso Screaming frog desde hace mas de 10años, y cada vez que me toca explicar esta herramienta siempre la defino como LA GRAN HERRAMIENTA SEO, porque sin duda, es una de las herramientas más completas para auditar una web.
Screaming Frog en una herramienta de scraping SEO, es decir, no solo rastrea URLs, sino que también puede extraer información concreta de cada página: textos, migas de pan, valoraciones, precios, autores, fechas, correos electrónicos, datos estructurados, bloques de contenido, fichas de producto o cualquier elemento presente en el HTML de una URL.
Para un consultor SEO, esta opción de poder extraer cualquier elemento HTML es especialmente útil porque permite analizar contenido a gran escala. En lugar de revisar manualmente decenas, cientos o miles de páginas, puedes configurar una extracción y obtener los datos en bloque para analizarlos después en Excel, Google Sheets, Looker Studio o cualquier otra herramienta de análisis, y si hablamos de IA, pues ya podemos imaginar que tenemos que es una forma mas de «usar IA en tareas SEO«.
- Qué es la extracción personalizada de Screaming Frog
- Para qué sirve extraer contenido con Screaming Frog en SEO
- Qué necesitas saber antes de extraer contenido de una web
- 1. Qué contenido quieres extraer exactamente
- 2. En qué etiqueta o bloque HTML está el contenido
- 3. Si el contenido está en HTML estático o se carga con JavaScript
- 4. Si la estructura es igual en todas las URLs
- 5. Si necesitas extraer texto, HTML o atributos
- 6. Qué método encaja mejor: XPath, CSSPath o regex
- 7. Si el selector extrae demasiado o demasiado poco
- 8. Si el contenido extraído tendrá valor SEO o no.
- Tipos de extracción personalizada en Screaming Frog
- Cómo extraer texto de una web con Screaming Frog paso a paso
- Cómo extraer el texto principal de una web con Screaming Frog
- Cómo extraer migas de pan con Screaming Frog
- Cómo extraer valoraciones y reseñas con Screaming Frog
- Cómo extraer correos electrónicos con Screaming Frog
- Cómo scrapear con Screaming Frog de forma responsable
- Distintas formas de extraer texto de una web con Screaming Frog
- Ejemplo práctico de extracción SEO con Screaming Frog
- Errores habituales al hacer extracciones personalizadas
- Consejos SEO para aprovechar mejor la extracción personalizada
- Cómo exportar y trabajar los datos extraídos
En esta guía vamos a ver qué es la extracción personalizada de Screaming Frog, qué necesitas identificar antes de extraer contenido, qué tipos de extracción existen y cómo utilizarla paso a paso para extraer texto de una web de forma ordenada, útil y accionable para SEO.
Qué es la extracción personalizada de Screaming Frog
La extracción personalizada de Screaming Frog, también conocida como Custom Extraction, es una funcionalidad que permite extraer datos concretos del código HTML de una página durante el rastreo.
En lugar de limitarte a los datos SEO estándar que Screaming Frog recopila por defecto, puedes configurar reglas para decirle a la herramienta exactamente qué información quieres obtener.
¿Que puedes extraer con screaming frog de una web?
Con la opción de extracción personalizada, puedes extraer:
- El texto principal de una o varias página.
- Las migas de pan o breadcrumbs.
- El nombre del autor de uno o varios artículos.
- La fecha de publicación de un post.
- Las valoraciones de cientos de productos de un ecommerce.
- El número de reseñas de un producto.
- El precio de uno o varios productos.
- Correos electrónicos visibles en la página.
- Textos de FAQs.
- Contenido de fichas de productos.
- Datos incluidos en etiquetas específicas.
- Información presente en JSON-LD o datos estructurados.
- Fragmentos concretos del HTML.
Desde una perspectiva SEO, esto es especialmente útil cuando necesitas analizar muchas URLs a la vez y no quieres revisar página por página de forma manual.
Por ejemplo, si tienes una web con 2.000 fichas de producto, puedes usar Screaming Frog para comprobar si todas tienen descripción, si muestran valoraciones, si incluyen migas de pan, si tienen bloque de preguntas frecuentes o si presentan datos comerciales relevantes para el usuario.
Para qué sirve extraer contenido con Screaming Frog en SEO
La extracción personalizada tiene muchas aplicaciones prácticas en una auditoría SEO. No se trata únicamente de “sacar textos”, sino de obtener datos que ayuden a tomar decisiones. Screaming Frog permite configurar extracciones mediante XPath, CSSPath y regex, y puede extraer datos tanto del HTML original como del HTML renderizado si se activa el renderizado JavaScript.
Con estas bondades, veamos para que se puede usar esta opción de la extracción de contenido de Screaming Frog.
Auditar contenido principal
Puedes extraer el texto principal de cada URL para revisar si hay páginas con poco contenido, contenido duplicado, textos demasiado genéricos o landings sin suficiente profundidad semántica.
Esto es especialmente útil en webs grandes, ecommerce, blogs con mucho histórico o proyectos donde se han generado muchas páginas con plantillas similares.
Revisar fichas de producto
En ecommerce, permite analizar si todas las fichas tienen descripción, precio, disponibilidad, valoraciones, número de opiniones o atributos técnicos.
También ayuda a detectar fichas incompletas, productos sin información comercial suficiente o páginas donde ciertos módulos no se están mostrando correctamente.
Comprobar migas de pan
Las migas de pan ayudan a entender la arquitectura de la web y pueden reforzar el enlazado interno. Con una extracción personalizada puedes comprobar si están presentes y si reflejan correctamente la jerarquía del sitio.
Esto resulta muy útil cuando se quiere auditar una arquitectura web, revisar categorías, detectar rutas inconsistentes o reconstruir la estructura real de un sitio a partir de sus breadcrumbs.
Detectar datos visibles importantes
Puedes extraer teléfonos, emails, direcciones, nombres de autor, fechas de publicación, categorías o cualquier bloque visible que sea importante para el negocio.
Por ejemplo, en una auditoría SEO local podrías revisar si todas las páginas de ubicación muestran dirección y teléfono. En un blog, podrías comprobar si todos los artículos muestran autor y fecha. En un ecommerce, podrías revisar si todos los productos muestran precio, disponibilidad y valoración.
Validar plantillas
Si trabajas con una web grande, Screaming Frog te permite revisar si una plantilla se está aplicando bien en todas las URLs.
Por ejemplo, puedes comprobar si todas las páginas de producto muestran correctamente valoraciones, si todas las entradas del blog tienen autor y fecha, o si todas las categorías tienen texto introductorio.
Analizar contenido renderizado con JavaScript
Si la web carga contenido mediante JavaScript, Screaming Frog puede extraer datos del HTML renderizado siempre que se active el modo de renderizado JavaScript. Esto es importante en webs modernas desarrolladas con frameworks o CMS que no muestran todo el contenido directamente en el HTML inicial.
si todas estas funciones luego las unes a sistemas IA, pues los tiempos logramos optimizarlos y mejorar en su análisis.
Qué necesitas saber antes de extraer contenido de una web
Antes de configurar una extracción personalizada en Screaming Frog, lo más importante es entender dónde está el contenido que quieres extraer dentro del HTML de la página.
Screaming Frog no “adivina” automáticamente qué bloque te interesa, por ello, necesitamos decirle una ruta, un selector o un patrón para localizar ese contenido. Esa ruta puede definirse mediante XPath, CSSPath o regex, dependiendo de cómo esté construido el elemento que quieres extraer.
Por eso, antes de crear una extracción personalizada, necesitas identificar varios elementos:
1. Qué contenido quieres extraer exactamente
El primer paso es definir el objetivo de la extracción.
No es lo mismo extraer:
- Todo el texto visible de una página.
- Solo el contenido principal.
- La descripción de un producto.
- Las migas de pan.
- El precio.
- Las valoraciones.
- El número de reseñas.
- El autor de un artículo.
- La fecha de publicación.
- Los correos electrónicos visibles.
- Un bloque de preguntas frecuentes.
Cuanto más concreto sea el objetivo, más limpia será la extracción.
Por ejemplo, si extraes todo el <body>, obtendrás mucho contenido, pero también incluirás menú, footer, cabecera, botones, textos legales y otros elementos repetidos. En cambio, si identificas que el contenido principal está dentro de <main>, <article> o una clase específica como .entry-content, la extracción será mucho más útil para SEO.
2. En qué etiqueta o bloque HTML está el contenido
Una vez definido el contenido que quieres extraer, debes inspeccionar la página para localizarlo en el HTML.
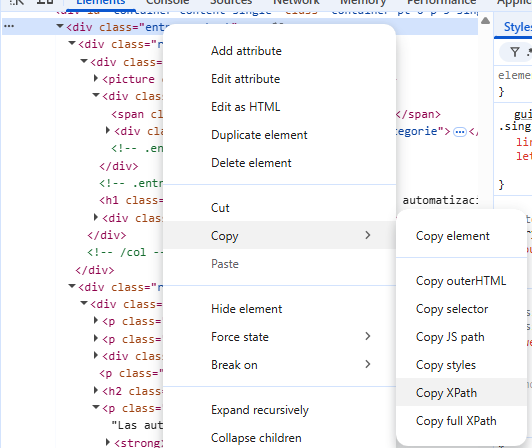
Para hacerlo, abre una URL en Chrome, haz clic derecho sobre el elemento que quieres extraer y selecciona:
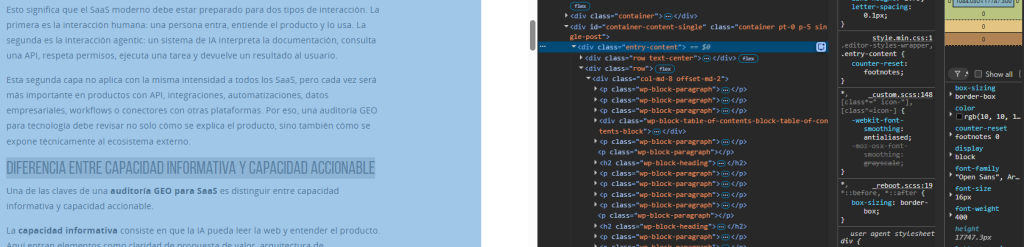
Ahí debes fijarte en elementos como:
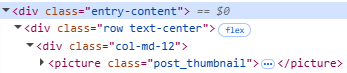
<main>
<article>
<div class="entry-content">
<div class="product-description">
<nav class="breadcrumb">
<span class="rating">
Estos elementos te ayudarán a construir la regla de extracción.
Por ejemplo, si el texto principal está dentro de:
Podrías usar un XPath como:
O un selector CSS como:
3. Si el contenido está en HTML estático o se carga con JavaScript
Otro punto clave es comprobar si el contenido está disponible en el HTML inicial o si se carga después mediante JavaScript.
Esto es importante porque, si Screaming Frog rastrea la web en modo HTML y el contenido se carga mediante JavaScript, puede que la extracción aparezca vacía.
En ese caso, debes activar el renderizado JavaScript desde:
Configuration > Spider > Rendering > JavaScript
Después, vuelve a lanzar el rastreo.
Esto es habitual en webs modernas creadas con frameworks, ecommerce personalizados, algunos CMS visuales o páginas donde las valoraciones, precios o módulos dinámicos se cargan después de la carga inicial.
4. Si la estructura es igual en todas las URLs
Antes de lanzar un rastreo completo, conviene probar la extracción en varias URLs del mismo tipo.
Por ejemplo, si estás extrayendo descripciones de producto, revisa al menos 3 o 4 fichas diferentes. Puede ocurrir que una ficha use:
<div class="product-description">
Pero otra use:
<div class="short-description">
O que algunas páginas no tengan ese bloque.
Desde una perspectiva SEO, esto también es interesante porque permite detectar inconsistencias de plantilla. Si la misma extracción funciona en unas URLs y en otras no, puede que haya diferencias técnicas o de contenido que deban revisarse.
5. Si necesitas extraer texto, HTML o atributos
Cuando configuras la extracción en Screaming Frog, no solo tienes que indicar el elemento. También debes decidir qué quieres extraer de ese elemento.
Las opciones más habituales son:
Extract Text
Extract Inner HTML
Extract HTML Element
Extract Attribute
Para una auditoría de contenido SEO, normalmente usarás Extract Text, porque quieres quedarte con el texto visible.
Por ejemplo:
XPath: //main
Extracción: Extract Text
Esto extraería el texto visible dentro del bloque <main>.
En cambio, si quieres revisar enlaces, etiquetas internas o marcado HTML, puede interesarte usar Extract Inner HTML.
Si quieres extraer un atributo concreto, como el enlace de una miga de pan, podrías usar XPath con atributo:
//nav[contains(@class,'breadcrumb')]//a/@href
6. Qué método encaja mejor: XPath, CSSPath o regex
Cuando ya sabes qué quieres extraer y dónde está, debes elegir el método adecuado.
XPath
XPath es muy flexible y permite seleccionar elementos según etiquetas, clases, atributos o posición dentro del HTML.
Es recomendable cuando necesitas precisión.
Ejemplos:
//h1
//main
//div[contains(@class,'product-description')]
//*[@itemprop='ratingValue']
CSSPath
CSSPath suele ser más sencillo si el contenido está dentro de clases o etiquetas claras.
Ejemplos:
h1
main
.product-description
.breadcrumb a
Es una buena opción cuando el HTML está bien estructurado y los selectores son fáciles de identificar.
Regex
Regex es útil cuando quieres localizar patrones de texto, no necesariamente elementos HTML concretos.
Por ejemplo, para extraer correos electrónicos:
[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}
O teléfonos:
(\+34\s?)?[6789]\d{2}[\s.-]?\d{3}[\s.-]?\d{3}
Regex es especialmente útil cuando el dato puede aparecer en distintas partes de la página, pero mantiene una estructura reconocible.
7. Si el selector extrae demasiado o demasiado poco
Una buena extracción personalizada debe ser precisa.
Si el selector es demasiado amplio, extraerá ruido. Por ejemplo:
//body
Puede ser útil para una primera prueba, pero normalmente incluirá navegación, footer, cabecera y textos repetidos.
Si el selector es demasiado específico, puede fallar en muchas URLs.
Por ejemplo:
//div[@class='product-description active desktop only']
Puede dejar de funcionar si cambia mínimamente una clase.
Por eso, muchas veces es mejor usar expresiones más flexibles como:
//div[contains(@class,'product-description')]
Esta regla busca cualquier div que contenga esa clase, aunque tenga otras clases adicionales.
8. Si el contenido extraído tendrá valor SEO o no.
Antes de hacer una extracción masiva, conviene preguntarse qué vas a hacer después con esos datos.
Una extracción personalizada tiene sentido cuando ayuda a responder preguntas como:
- ¿Qué URLs tienen poco contenido?
- ¿Qué fichas de producto no tienen descripción?
- ¿Qué categorías no tienen texto SEO?
- ¿Qué páginas no muestran breadcrumbs?
- ¿Qué productos no tienen valoraciones?
- ¿Qué artículos no tienen autor o fecha?
- ¿Qué páginas muestran emails visibles?
- ¿Qué plantillas no están funcionando correctamente?
- ¿Qué URLs tienen contenido duplicado o demasiado similar?
El objetivo no es solo scrapear contenido con Screaming Frog, sino convertir esa extracción en una base de análisis para tomar mejores decisiones SEO.
Tipos de extracción personalizada en Screaming Frog
Screaming Frog permite configurar extracciones personalizadas principalmente mediante tres métodos:
- XPath.
- CSSPath.
- Regex.
Cada método tiene una lógica diferente y conviene elegir uno u otro según el tipo de dato que quieras extraer.
Extracción personalizada con XPath
XPath es uno de los métodos más utilizados para extraer información con Screaming Frog. Sirve para navegar por la estructura del HTML y seleccionar elementos concretos.
Es muy útil cuando quieres extraer datos de etiquetas, clases, atributos o bloques específicos.
Por ejemplo, si quieres extraer todos los H1 de una página, puedes usar:
//h1
Si quieres extraer el contenido principal dentro de una etiqueta <main>, puedes usar:
//main
Si quieres extraer el contenido de un bloque con una clase concreta, puedes usar:
//div[contains(@class,'entry-content')]
XPath es especialmente útil cuando conoces la estructura de la página y quieres seleccionar elementos de forma precisa.
Ejemplos útiles de XPath para SEO
Extraer el H1:
//h1
Extraer todos los H2:
//h2
Extraer el primer párrafo de una página:
(//p)[1]
Extraer el texto principal dentro de <main>:
//main
Extraer contenido dentro de <article>:
//article
Extraer un bloque con clase “content”:
//div[contains(@class,'content')]
Extraer un bloque con clase “product-description”:
//div[contains(@class,'product-description')]
Extraer enlaces internos de breadcrumbs:
//nav[contains(@class,'breadcrumb')]//a
Extraer el atributo href de enlaces dentro de breadcrumbs:
//nav[contains(@class,'breadcrumb')]//a/@href
Extraer elementos con atributo itemprop="ratingValue":
//*[@itemprop='ratingValue']
Extraer elementos con atributo itemprop="reviewCount":
//*[@itemprop='reviewCount']
Extracción personalizada con CSSPath
CSSPath, o selector CSS, es otra forma de seleccionar elementos del HTML. Es muy habitual para quienes están acostumbrados a trabajar con CSS o con inspección de elementos en el navegador.
Por ejemplo, si quieres extraer el contenido de un bloque con la clase entry-content, puedes usar:
.entry-content
Si quieres extraer el contenido de una ficha de producto:
.product-description
Si quieres extraer migas de pan:
.breadcrumb a
CSSPath suele ser más sencillo de leer que XPath, aunque XPath normalmente ofrece más flexibilidad para casos complejos.
Ejemplos útiles de CSSPath
Extraer el H1:
h1
Extraer todos los H2:
h2
Extraer contenido de un artículo:
article
Extraer contenido principal:
main
Extraer una descripción de producto:
.product-description
Extraer migas de pan:
.breadcrumb a
Extraer valoraciones:
.rating
Extraer número de opiniones:
.review-count
Extraer precio:
.price
Extracción personalizada con regex
Regex, o expresiones regulares, sirve para encontrar patrones concretos dentro del HTML o del texto.
Es muy útil cuando el dato no está dentro de una etiqueta clara, pero sí sigue un patrón reconocible.
Por ejemplo, para extraer correos electrónicos visibles en una página, puedes usar una expresión regular como:
[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}
También puedes usar regex para buscar patrones como teléfonos, códigos, IDs, fragmentos de schema, referencias internas o cualquier dato que tenga una estructura repetible.
Ejemplos útiles de regex
Extraer correos electrónicos:
[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}
Extraer teléfonos en formato español aproximado:
(\+34\s?)?[6789]\d{2}[\s.-]?\d{3}[\s.-]?\d{3}
Extraer URLs:
https?:\/\/[^\s"']+
Extraer códigos postales españoles:
\b\d{5}\b
Regex es potente, pero también puede generar ruido si la expresión no está bien afinada. Por eso, para auditorías SEO, suele ser recomendable usar XPath o CSSPath cuando el dato está claramente estructurado en el HTML, y reservar regex para patrones más generales.
Extracción visual personalizada en Screaming Frog
Además de configurar manualmente XPath, CSSPath o regex, Screaming Frog también permite usar la extracción visual personalizada.
Esta opción es muy útil si no tienes experiencia técnica o si quieres seleccionar elementos directamente desde una vista visual de la página. Screaming Frog permite abrir un navegador integrado, seleccionar el elemento que quieres extraer y generar una ruta de extracción a partir de esa selección.
Para usarla, debes ir a:
Configuration > Custom > Extraction
Después, dentro del extractor, puedes usar el icono de navegador para abrir la página, hacer clic en el elemento que quieres extraer y generar el selector.
Desde una perspectiva SEO, esta opción es muy práctica para extraer datos como:
- Autor de un artículo.
- Fecha de publicación.
- Precio de producto.
- Valoración.
- Categoría.
- Breadcrumbs.
- Texto de una ficha.
- Bloques visibles de contenido.
Aunque la extracción visual ayuda mucho, siempre conviene revisar el selector generado y probarlo en varias URLs. Un selector que funciona en una página puede no ser válido para todas si la plantilla cambia.
Cómo extraer texto de una web con Screaming Frog paso a paso
A continuación vemos el proceso completo para extraer contenido de una web usando Screaming Frog.
Paso 1: abrir Screaming Frog e introducir la URL
Abre Screaming Frog SEO Spider e introduce la URL de la web que quieres rastrear.
Por ejemplo:
https://www.ejemplo.com/
Antes de iniciar el rastreo, conviene revisar la configuración para asegurarte de que Screaming Frog podrá acceder correctamente al contenido.
Paso 2: revisar la configuración del rastreo
Ve a:
Configuration > Spider
Comprueba que el rastreo de HTML está activado.
Si la web carga contenido mediante JavaScript, ve a:
Configuration > Spider > Rendering
Y selecciona:
JavaScript
Esto es importante en webs donde el contenido no aparece directamente en el HTML inicial, sino que se carga después mediante scripts.
Paso 3: configurar la extracción personalizada
Para configurar una extracción personalizada, ve a:
Configuration > Custom > Extraction
Dentro de esta sección puedes añadir uno o varios extractores.
Cada extractor debe tener:
- Nombre del extractor.
- Tipo de extracción.
- Regla de extracción.
- Modo de extracción.
Por ejemplo:
Nombre: Texto principal
Tipo: XPath
Regla: //main
Extracción: Extract Text
Paso 4: elegir el tipo de dato que quieres extraer
Screaming Frog permite extraer el texto, el HTML interno, el elemento HTML completo o atributos concretos.
Las opciones más habituales son:
Extract Text
Extrae únicamente el texto visible del elemento seleccionado.
Es la opción más útil cuando quieres analizar contenido desde una perspectiva SEO.
Ejemplo:
//main
Resultado esperado: el texto principal de la página.
Extract Inner HTML
Extrae el HTML interno del elemento seleccionado.
Es útil si quieres revisar etiquetas, enlaces, marcado interno o estructura del bloque.
Extract HTML Element
Extrae el elemento HTML completo.
Puede ser útil si necesitas auditar cómo está construido un bloque concreto.
Extract Attribute
Permite extraer valores concretos de atributos.
Por ejemplo, si quieres extraer el destino de los enlaces de las migas de pan, podrías usar:
//nav[contains(@class,'breadcrumb')]//a/@href
Para la mayoría de trabajos SEO de contenido, lo más habitual será usar Extract Text.
Paso 5: lanzar el rastreo
Una vez configurada la extracción personalizada, vuelve a la pantalla principal de Screaming Frog y pulsa:
Start
Screaming Frog empezará a rastrear la web y aplicará las reglas de extracción a cada URL.
Paso 6: revisar los resultados
Cuando el rastreo avance o finalice, ve a la pestaña:
Custom Extraction
Ahí verás las URLs rastreadas y las columnas correspondientes a cada extracción personalizada configurada.
Por ejemplo:
URL | Texto principal | Breadcrumbs | Rating | Email
Si una celda aparece vacía, puede deberse a varias razones:
- La regla XPath o CSS no coincide con el HTML.
- El contenido no existe en esa URL.
- El contenido se carga por JavaScript y no has activado el renderizado.
- La clase o estructura HTML cambia según el tipo de página.
- El dato está en un iframe o recurso externo.
- La URL no devuelve un código 200.
- El contenido está bloqueado para el rastreador.
Paso 7: exportar la extracción personalizada en bloque
Para exportar los resultados, puedes ir a la pestaña:
Custom Extraction
Y hacer clic en:
Export
También puedes usar la opción de exportación masiva:
Bulk Export > Custom Extraction
De esta forma puedes descargar en bloque todos los datos extraídos y trabajarlos después en Excel, Google Sheets, Looker Studio, Power BI o cualquier herramienta de análisis.
Para SEO, lo más práctico es cruzar la extracción personalizada con datos como:
- URL.
- Código de estado.
- Indexabilidad.
- Title.
- Meta description.
- H1.
- Canonical.
- Profundidad de clic.
- Inlinks.
- Tipo de plantilla.
- Texto extraído.
- Datos específicos extraídos.
Así puedes analizar no solo qué contenido tiene cada URL, sino también si ese contenido está alineado con su función SEO.
La pestaña de Custom Extraction trabaja junto con la configuración de extracción personalizada y permite revisar los datos extraídos durante el rastreo. Screaming Frog indica que pueden configurarse hasta 100 extractores personalizados y que esta extracción se aplica sobre URLs con contenido HTML.
Cómo extraer el texto principal de una web con Screaming Frog
Una de las tareas más habituales es extraer el texto principal de cada URL.
Hay varias formas de hacerlo.
Opción 1: extraer todo el body
Puedes usar:
//body
Esta opción extrae todo el contenido textual de la página, pero suele incluir mucho ruido: menú, footer, cabecera, textos legales, botones, breadcrumbs y otros elementos repetidos.
Es útil como primera prueba, pero no siempre es la mejor opción para un análisis SEO limpio.
Opción 2: extraer el contenido de main
Puedes usar:
//main
Esta suele ser una opción más limpia si la web está bien estructurada.
Opción 3: extraer el contenido de article
Para blogs, noticias o guías, puedes probar:
//article
Esta opción suele funcionar bien en artículos editoriales.
Opción 4: extraer una clase concreta
Si el contenido principal está dentro de una clase específica, puedes usar:
//div[contains(@class,'entry-content')]
O con CSSPath:
.entry-content
También puedes adaptar la regla a clases como:
.post-content
.page-content
.product-description
.cms-content
La clave está en inspeccionar el HTML de la página y localizar el contenedor que agrupa el contenido que realmente te interesa.
Cómo extraer migas de pan con Screaming Frog
Las migas de pan, o breadcrumbs, son muy útiles para analizar la arquitectura de una web. Ayudan a entender cómo se organizan las páginas y qué jerarquía se está comunicando tanto al usuario como a los buscadores.
Para extraer migas de pan, primero debes inspeccionar el HTML y ver cómo están marcadas.
Algunas webs usan una etiqueta <nav> con clase breadcrumb. En ese caso podrías usar:
//nav[contains(@class,'breadcrumb')]
Si quieres extraer solo los textos de los enlaces de las migas de pan:
//nav[contains(@class,'breadcrumb')]//a
Con CSSPath, podrías usar:
.breadcrumb a
Si quieres extraer las URLs de cada enlace dentro de las migas de pan:
//nav[contains(@class,'breadcrumb')]//a/@href
Si la web usa datos estructurados BreadcrumbList en JSON-LD, también podrías extraer el bloque de script que contiene esa información, aunque en ese caso suele ser más práctico revisar directamente la pestaña de datos estructurados de Screaming Frog o crear una extracción específica sobre el script.
Cómo extraer valoraciones y reseñas con Screaming Frog
En ecommerce, marketplaces o webs con fichas de producto, puede ser muy útil extraer valoraciones y número de reseñas.
Por ejemplo, si la valoración está marcada con itemprop="ratingValue", puedes usar:
//*[@itemprop='ratingValue']
Si el número de reseñas está marcado con itemprop="reviewCount", puedes usar:
//*[@itemprop='reviewCount']
También puedes probar selectores CSS si la web usa clases claras:
.rating
.review-count
.product-rating
.stars-rating
Este tipo de extracción permite detectar fichas sin reseñas, productos con baja valoración o páginas donde el marcado de reviews no se está mostrando correctamente.
Desde un punto de vista SEO, también puede servir para revisar coherencia entre el contenido visible, los datos estructurados y la información que Google puede interpretar.
Cómo extraer correos electrónicos con Screaming Frog
Si necesitas detectar emails visibles en una web, puedes hacerlo mediante regex.
Una expresión regular básica para correos electrónicos sería:
[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}
Esta extracción puede ser útil para:
- Detectar emails visibles en páginas públicas.
- Auditar páginas de contacto.
- Localizar correos antiguos.
- Revisar posibles datos personales expuestos.
- Comprobar si ciertas páginas contienen información de contacto.
Eso sí, hay que utilizar esta extracción con criterio. No se trata de recopilar datos de forma indiscriminada, sino de auditar información visible en una web propia o en un proyecto donde tengas autorización para trabajar.
Cómo scrapear con Screaming Frog de forma responsable
Screaming Frog puede utilizarse como herramienta de scraping, pero debe usarse con responsabilidad.
Antes de rastrear una web, conviene tener en cuenta:
- Si tienes autorización para analizar esa web.
- Si el rastreo puede sobrecargar el servidor.
- Si debes respetar robots.txt.
- Si necesitas limitar la velocidad de rastreo.
- Si estás extrayendo datos personales.
- Si la extracción tiene una finalidad legítima de auditoría o análisis.
Para limitar la velocidad de rastreo, puedes ir a:
Configuration > Speed
Y ajustar el número de threads y URLs por segundo.
En auditorías SEO profesionales, lo habitual es usar Screaming Frog sobre webs propias, webs de clientes o entornos donde existe permiso para realizar el análisis.
Distintas formas de extraer texto de una web con Screaming Frog
No existe una única forma correcta de extraer texto. La mejor opción depende de la estructura de la web y del objetivo del análisis.
Extraer todo el contenido textual
Usa:
//body
Ventaja: recoge todo el texto.
Desventaja: incluye ruido de navegación, footer y elementos repetidos.
Extraer solo el contenido principal
Usa:
//main
Ventaja: suele ser más limpio.
Desventaja: no todas las webs usan correctamente la etiqueta <main>.
Extraer artículos de blog
Usa:
//article
Ventaja: útil para blogs, noticias y guías.
Desventaja: puede no funcionar en plantillas mal estructuradas.
Extraer descripciones de producto
Usa:
//div[contains(@class,'product-description')]
O con CSSPath:
.product-description
Ventaja: ideal para ecommerce.
Desventaja: depende de que la clase sea consistente.
Extraer bloques de FAQ
Usa:
//div[contains(@class,'faq')]
O con CSSPath:
.faq
Ventaja: permite auditar preguntas frecuentes en bloque.
Desventaja: puede variar mucho según el CMS o el maquetador.
Extraer textos por patrones
Usa regex cuando el dato no está bien estructurado, pero sigue un patrón reconocible.
Ejemplo para emails:
[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}
Ventaja: útil para datos con estructura repetible.
Desventaja: puede generar falsos positivos si no se ajusta bien.
Ejemplo práctico de extracción SEO con Screaming Frog
Imagina que quieres auditar un ecommerce y necesitas comprobar si todas las fichas de producto tienen:
- Descripción de producto.
- Migas de pan.
- Valoración media.
- Número de reseñas.
- Precio visible.
Podrías configurar los siguientes extractores:
Extractor 1: descripción de producto
Nombre: Descripción producto
Tipo: XPath
Regla: //div[contains(@class,'product-description')]
Extracción: Extract Text
Extractor 2: migas de pan
Nombre: Breadcrumbs
Tipo: XPath
Regla: //nav[contains(@class,'breadcrumb')]
Extracción: Extract Text
Extractor 3: valoración
Nombre: Rating
Tipo: XPath
Regla: //*[@itemprop='ratingValue']
Extracción: Extract Text
Extractor 4: número de reseñas
Nombre: Reviews
Tipo: XPath
Regla: //*[@itemprop='reviewCount']
Extracción: Extract Text
Extractor 5: precio
Nombre: Precio
Tipo: CSSPath
Regla: .price
Extracción: Extract Text
Después de lanzar el crawl, podrías exportar los resultados y filtrar:
- URLs sin descripción.
- Productos sin breadcrumbs.
- Productos sin valoración.
- Productos sin reseñas.
- Productos sin precio visible.
- Plantillas con extracción vacía.
- Diferencias entre tipos de producto.
Este análisis permite detectar problemas de contenido y plantilla de forma mucho más rápida que revisando URL por URL.
Errores habituales al hacer extracciones personalizadas
Al trabajar con Custom Extraction, es normal que al principio algunas extracciones no funcionen. Estos son los errores más habituales.
Usar una clase demasiado genérica
Por ejemplo:
.content
Puede aparecer en muchos bloques distintos y extraer más información de la necesaria.
Extraer desde body sin limpiar después
Extraer todo el body puede servir como prueba, pero normalmente genera demasiado ruido.
No activar JavaScript Rendering
Si el contenido se carga por JavaScript y Screaming Frog rastrea solo el HTML original, puede que la extracción salga vacía.
No probar la regla en varias URLs
Una regla puede funcionar en una plantilla, pero fallar en otra. Es recomendable probar siempre en varios tipos de página.
Confundir texto visible con HTML
Si quieres analizar contenido, normalmente debes usar Extract Text. Si extraes HTML, tendrás etiquetas y código que pueden dificultar el análisis.
No revisar códigos de estado
Si una URL devuelve 3xx, 4xx o 5xx, la extracción puede no comportarse como esperas. Conviene cruzar siempre los resultados con el status code.
Consejos SEO para aprovechar mejor la extracción personalizada
Para sacar más valor de Screaming Frog, conviene plantear la extracción como una auditoría, no como una simple descarga de datos.
Define antes qué quieres comprobar
No extraigas datos por extraer. Define una pregunta SEO concreta.
Por ejemplo:
- ¿Todas las categorías tienen texto introductorio?
- ¿Todas las fichas tienen descripción única?
- ¿Las migas de pan reflejan bien la arquitectura?
- ¿Los artículos tienen autor y fecha?
- ¿Las páginas de producto muestran valoraciones?
- ¿Hay emails visibles que deberían sustituirse por formularios?
- ¿Las páginas transaccionales tienen contenido suficiente?
Segmenta por tipo de URL
No analices igual una home, una categoría, una ficha de producto, un artículo de blog y una landing.
Después de exportar, crea una columna de tipo de página y analiza cada grupo por separado.
Cruza la extracción con métricas SEO
La extracción personalizada gana mucho valor cuando la cruzas con datos de:
- Google Search Console.
- Google Analytics 4.
- Ahrefs.
- Semrush.
- Sistrix.
- Datos de conversión.
- Datos de enlazado interno.
- Profundidad de clic.
Así puedes priorizar mejor. No es lo mismo una URL sin texto que no recibe tráfico que una categoría estratégica con muchas impresiones y una descripción pobre.
Revisa contenido duplicado o demasiado similar
Si extraes el texto principal de varias URLs, puedes detectar patrones repetidos, plantillas con contenido duplicado o páginas que necesitan una optimización editorial.
Usa la extracción para validar implementaciones
Después de un cambio en plantilla, puedes rastrear la web y comprobar si el nuevo bloque aparece correctamente en todas las URLs.
Por ejemplo:
- Nuevo bloque de FAQs.
- Nuevo módulo de enlaces internos.
- Nueva zona de reviews.
- Nueva descripción SEO.
- Nuevo breadcrumb.
- Nuevo marcado visible de producto.
Cómo exportar y trabajar los datos extraídos
Una vez tengas los datos en la pestaña Custom Extraction, exporta el archivo y trabaja con filtros.
Una tabla útil podría incluir:
URL
Status Code
Indexability
Title
Meta Description
H1
Canonical
Tipo de página
Texto principal
Breadcrumbs
Rating
Reviews
Precio
Email
Después puedes crear filtros como:
- Texto principal vacío.
- Breadcrumbs vacíos.
- Rating vacío.
- Reviews vacío.
- Precio vacío.
- Email detectado.
- Descripciones demasiado cortas.
- Contenido duplicado.
- Páginas indexables sin contenido.
- Páginas importantes con contenido pobre.
La extracción personalizada de Screaming Frog es una de las funciones más útiles para cualquier profesional SEO que necesite analizar webs de forma escalable. Gracias a XPath, CSSPath y regex, puedes extraer prácticamente cualquier dato presente en el HTML de una página: textos principales, migas de pan, valoraciones, correos, precios, autores, fechas, FAQs, descripciones de producto o fragmentos concretos de código.
La clave está en usar esta funcionalidad con un objetivo claro. No se trata solo de scrapear una web, sino de obtener información que permita tomar mejores decisiones SEO: detectar contenidos pobres, validar plantillas, revisar arquitectura, comprobar datos visibles, encontrar errores y priorizar acciones.
Bien utilizada, la extracción personalizada convierte a Screaming Frog en mucho más que un crawler: lo transforma en una herramienta de análisis masivo de contenido, estructura y calidad SEO.
Por: