

El avance de la Inteligencia Artificial generativa (IA) ha impulsado el consumo masivo de contenidos web para el entrenamiento de modelos como ChatGPT, Gemini, Claude, LLaMA, Perplexity y otros. Sin embargo, los propietarios de sitios web no siempre desean que su contenido se utilice libremente con ese propósito.
- ¿Qué es el archivo LLM.txt?
- ¿Qué problema resuelve el LLM.txt?
- ¿Por qué es importante usar el archivo LLM.txt?
- ¿Quién fomenta el uso de los archivos LLM.txt?
- Ventajas y Desventajas de usar archivos LLM.txt
- ¿Cómo debe estar estructurado un archivo LLM.txt?
- Contenido recomendado según el tipo de página
- Comandos comunes en el archivo LLM.txt
- Ejemplos de cómo va el LLM.txt
- Como especificar reglas para cada modelo de IA.
- Ejemplos completos de configuración de un archivo LLM.txt
- Como decidir si necesitas preparar un archivo LLM.txt
- Preguntas frecuentes sobre el archivo LLM.txt
¿Qué es el archivo LLM.txt?
El llm.txt es un archivo de texto plano situado en la raíz del dominio, destinado a comunicar a los modelos de IA alguna de las siguientes indicaciones:
- Qué contenido pueden utilizar
- Qué contenido no pueden usar
- Para qué fines (referencia, entrenamiento, indexación semántica, etc.)
- No sustituye al robots.txt, sino que lo complementa.
Es un archivo muy parecido al robots.txt, pero que en vez de permitir acceder o no a la web, indica lo que queremos que la herramienta IA haga con nuestro contenido.
¿Qué problema resuelve el LLM.txt?
Antes del llm.txt, los modelos de IA podían entrar a nuestro contenido y:
- Copiar contenido de páginas web públicas.
- Incorporarlo a sus datasets de entrenamiento.
- Utilizarlo para generar respuestas sin atribución ni referencia.
El archivo llm.txt permite dejar constancia pública y verificable de los permisos y restricciones del titular del sitio web.
¿Por qué es importante usar el archivo LLM.txt?
Utilizar los archivos LLM.txt permiten lo siguiente
| Motivo | Impacto |
| Protección de derechos de autor | Evita que contenido propietario se use para entrenar IA |
| Control sobre el uso del contenido | Define qué partes del sitio pueden ser utilizadas |
| Cumplimiento ético y transparencia | Las empresas indican su postura ante el uso de IA |
| Mitigar extracción indebida | Reduce la probabilidad de copia sistemática |
Aunque no hay un consenso sobre la utilidad de este archivo.
¿Quién fomenta el uso de los archivos LLM.txt?
El formato ha sido impulsado por:
- Desarrolladores de IA generativa
- Editoriales y medios que defienden autoría (NYT, BBC, Vox Media…)
- Empresas tecnológicas (OpenAI, Anthropic, Google, Meta…)
- Comunidades de SEO / Webmasters
- Organizaciones de gestión de derechos
Su adopción está en expansión intentando convertirse en un estándar de la gestión del contenido.
Ventajas y Desventajas de usar archivos LLM.txt
| Ventajas | Desventajas |
| Proporciona control explícito de uso del contenido | No es legal ni vinculante para todos los modelos IA |
| Facilita políticas claras para IA | Algunos actores pueden ignorarlo |
| Mejora transparencia y reputación digital | Requiere decisión estratégica previa |
| Permite enfoques flexibles según secciones | Requiere mantenimiento si cambia la web |
¿Cómo debe estar estructurado un archivo LLM.txt?
Al igual que los Robots.txt, los archivos LLM.txt tienen un formato definido y unas instrucciones que se definen a través de varios elementos claves, veamos dichos factores:
Formato que debe tener un archivo LLM.txt:
En cuanto al formato de los archivos LLM.txt podemos mencionar lo siguiente:
- Archivo de texto plano (.txt)
- Codificación UTF-8
- Debe situarse en la raíz del dominio
Ejemplo:
https://tudominio.com/llm.txt
Elementos clave en un archivo LLM.txt:
Entre los elementos a cuidar en un archivo LLM.txt, podemos mencionar los siguientes:
- User-Agent: modelos a los que aplica
- Allow: secciones permitidas
- Disallow: secciones prohibidas
- Policy: declaración explícita de uso del contenido
Contenido recomendado según el tipo de página
Si no tienes claro si tu contenido debes bloquearlo o no para los modelos de IA, ya sea para el entrenamiento o para su indexación, aquí te dejamos unas indicaciones claras sobre qué hacer en cada caso:
Secciones que habitualmente se permiten en un LLM.txt
| Tipo de contenido | Motivo | Estado recomendado |
| Blog educativo | Promueve visibilidad y reputación | Allow / Permitir indexación y referencia |
| Información institucional | Divulgación pública | Allow / Sin restricción |
| Páginas de destino públicas | Difusión comercial | Allow, pero sin entrenamiento |
Ejemplo:
Allow: /blog/
Allow: /nosotros/
Policy: Content may be referenced, but NOT used for training.
Secciones que habitualmente se deben restringir en un LLM.txt:
| Tipo de contenido | Riesgo | Estado recomendado |
| Ecommerce (carrito, checkout) | Datos sensibles | Disallow |
| Área privada / cuenta | Información personal | Disallow |
| PDF descargables | Propiedad intelectual directa | Disallow |
| Documentación interna / manuales | Derechos de autor | Disallow |
Ejemplo:
Disallow: /carrito/
Disallow: /checkout/
Disallow: /mi-cuenta/
Disallow: /manuales/
Disallow: /pdfs/
Policy: No training, no semantic indexing, no reproduction.
Comandos comunes en el archivo LLM.txt
A día de hoy, no existe un estándar oficial único (como sí ocurre con robots.txt). Sin embargo, se está consolidando un conjunto de directivas comunes que los principales modelos de IA ya reconocen.
Estas son las instrucciones (comandos) que pueden usarse en llm.txt:
| Comando | Qué hace | Ejemplo |
| User-Agent | Indica a qué modelo o servicio de IA se dirigen las reglas | User-Agent: * |
| Allow | Permite el acceso o uso del contenido indicado | Allow: /blog/ |
| Disallow | Prohíbe el acceso o el uso del contenido indicado | Disallow: /privado/ |
| Policy | Define el tipo de uso permitido (referencia, entrenamiento, etc.) | Policy: Content may be referenced but NOT used for training. |
| LLM (opcional en robots.txt) | Señala la ubicación del archivo llm.txt desde robots.txt | LLM: https://tudominio.com/llm.txt |
Comandos reconocidos opcionales:
| Comando | Función | Nota |
| Dataset | Indica explícitamente si el contenido puede entrar en datasets de IA | Soporte variable, adoptado por OpenAI y Perplexity |
| No-Archive | Evita la copia persistente del contenido | Útil en medios y contenidos con derechos |
| License / Terms | Enlaza a condiciones legales de uso del contenido | No es obligatorio, pero recomendable |
Ejemplo:
Dataset: disallow
No-Archive: true
License: https://tudominio.com/aviso-legal
Ejemplos de cómo va el LLM.txt
Si no sabes como debe estructurarse el archivo LLM.txt, aqui te dejamos algunos ejemplos sobre como deben redactarse dichos archivos:
Archivo LLM.txt si quieres permitir solo lectura y referencia (NO entrenamiento)
User-Agent: *
Allow: /
Policy: Content may be referenced to answer user queries, but may NOT be used for training or dataset creation.
Dataset: disallow
No-Archive: true
Archivo LLM.txt si quieres permitir el entrenamiento
User-Agent: *
Allow: /
Policy: Content may be used for research, indexing, and model training.
Dataset: allow
Archivo LLM.txt si quieres el Bloqueo total de tu contenido
User-Agent: *
Disallow: /
Policy: No training, no indexing, no extraction, no reproduction.
Dataset: disallow
No-Archive: true
Como especificar reglas para cada modelo de IA.
Así como en el robots.txt podemos dar indicaciones a cada bot, en el archivo LLM.txt podemos dar instrucciones a diferentes modelos de IA. A manera de ejemplo, podríamos tener:
User-Agent: OpenAI
Policy: Content may be referenced but NOT used for training.
User-Agent: Google-Extended
Disallow: /
Policy: No training.
User-Agent: Perplexity
Allow: /blog/
Disallow: /ebooks/
Ejemplos completos de configuración de un archivo LLM.txt
Si buscas ejemplos de como debe ir el archivo LLM.txt, aquí te dejo algunos casos:
LLM.txt que permite la referencia, pero no el entrenamiento:
User-Agent: *
Allow: /
Policy: Content may be referenced to answer user questions, but may NOT be used for training or fine-tuning.
LLM.txt que bloquea totalmente el contenido
User-Agent: *
Disallow: /
Policy: No training. No crawling. No content usage.
LLM.txt que permite todo (casos educativos / open source)
User-Agent: *
Allow: /
Policy: Content may be used for research, indexing, and training.
Como decidir si necesitas preparar un archivo LLM.txt
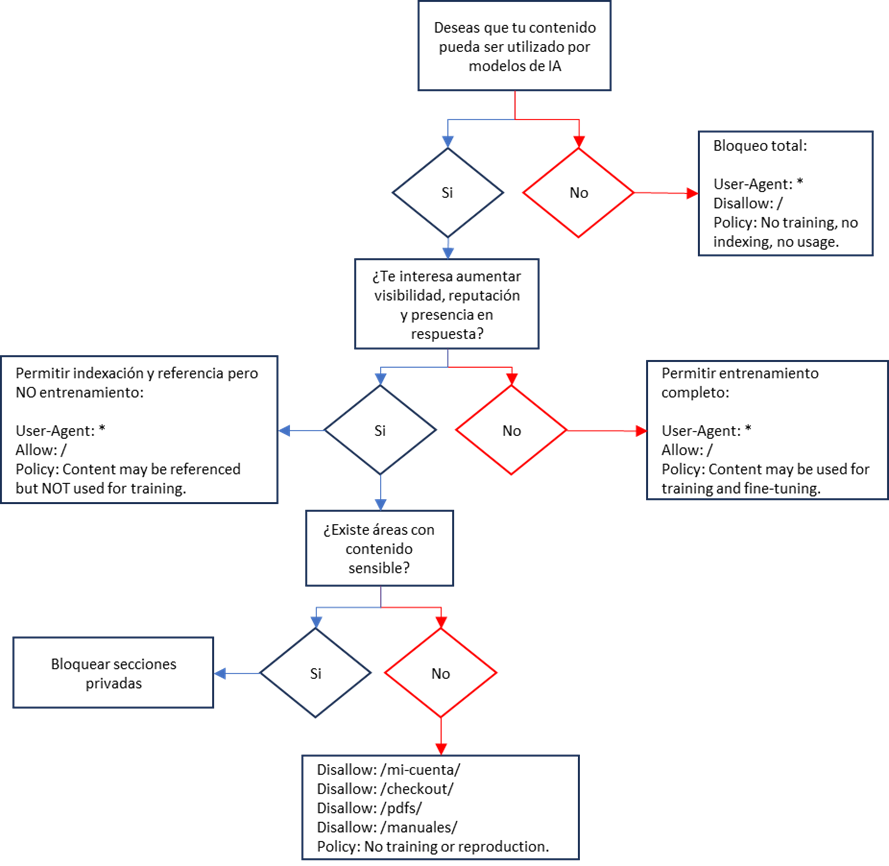
Preguntas frecuentes sobre el archivo LLM.txt
No. Google no usa llm.txt para el ranking.
No, pero se está convirtiendo en norma de control de contenido.
Las grandes empresas de IA (por ejemplo, OpenAI, Google, Meta, Anthropic, Perplexity) están comprometidas públicamente a respetar lo que un sitio web declare en llm.txt (igual que respetan robots.txt). Es decir, si en llm.txt indicas que NO quieres que tu contenido se use para entrenar IA, estas empresas lo respetarán y no incluirán tu contenido en sus datasets.
Sin embargo, no todos los actores del ecosistema IA son igual de responsables, ya que, existen:
– Modelos open-source entrenados por particulares
– Bots o scrapers no identificados
– Startups que no tienen políticas claras de uso de contenido
Estos actores podrían ignorar las reglas de llm.txt y seguir usando el contenido si lo encuentran accesible públicamente.
Sí, si cambias la estructura o la política de contenido debes cambiarlo.
El archivo llm.txt es la herramienta más efectiva actualmente para establecer una política clara sobre el uso de contenido de la web por parte de modelos de IA generativa.
No es perfecto, pero proporciona control, transparencia y protección, y su adopción es una práctica recomendada.
Si te gustó, guarda, comenta y comparte que quizás a alguien necesite de esta información.
Por: Alexis Petit


