Con el funcionamiento de los buscadores, Google, Yahoo, Bing, etc… sucede algo similar a lo que sucede con tecnologías como los microondas o los coches: todo el mundo los usa pero hay un buen número de personas que no saben exactamente cómo funcionan. A continuación, vamos a tratar de explicar de forma sencilla cómo es éste funcionamiento.
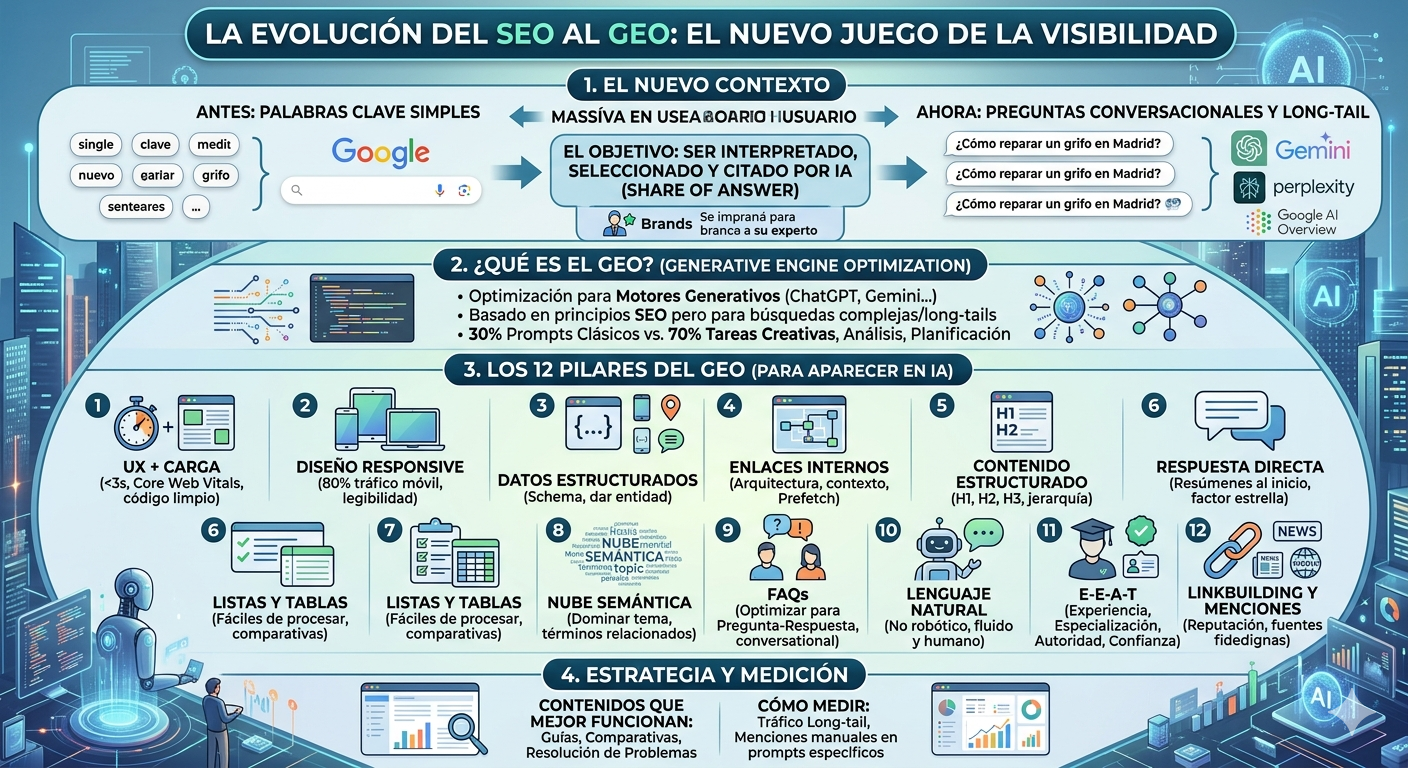
Lo primero es hablar del proceso de hallazgo e indexación de contenido (crawling and indexing en el idioma de Sheakspeare. Esta es la primera fase, de descubrimiento de contenido, necesaria para que el buscador pueda ofrecernos resultados cuando hacemos búsquedas. Contrario a lo que algunos piensan, cuando hacemos una búsqueda los buscadores no van a Internet en tiempo real a encontrar resultados relevantes. Los resultados que nos muestran los han encontrado e indexado las arañas o robtos del buscador con anterioridad.
Para esa fase de indexación de contenidos, el motor de búsqueda usa software conocido como robot o arañas, los cuales tienen la función de navegar Internet de forma automática, indexando cada URL que se encuentran y siguiendo los enlaces presentes en eses contenido para descubrir páginas adicionales.
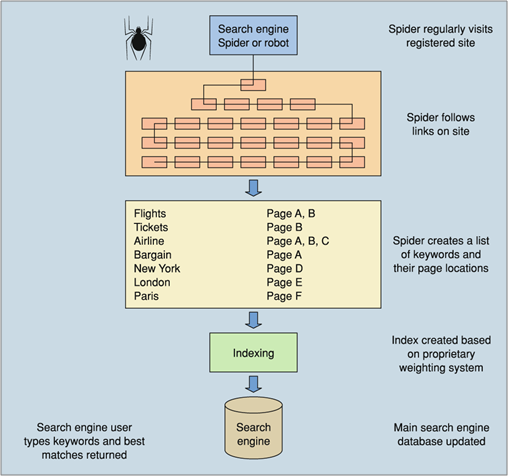
Para el buscador 1 URL = 1 documento, dos URLS distintas no deben mostrar el mismo documento o estaremos incurriendo en contenido duplicado. La indexación consiste en la lectura, compilación y anotación en el índice del contenido que encuentra en cada una de esas URLs.
Estos robots o arañas descubren nuevas páginas siguiendo los enlaces que se encuentran en las páginas que van indexando y haciendo peticiones desde el servidor de la misma manera que lo haría un navegador.
La indexación la realizan de los contenidos textuales mostrados mediante HTML que encuentren en cada página que visiten. Además, seguirán los enlaces en HTML que apunten a otras páginas, tanto textuales como de imagen. También podrán indexar y seguir enlaces en otros formatos como PDF, Word, etc…
Para que Google y el resto de los buscadores nos indexen no necesitamos “enviar” nuestro site a los buscadores ni usar ningún servicio de “alta en buscadores”. Hace 20 años sí era el caso. A día de hoy no hace falta.
Las arañas o spiders de los buscadores nos encontrarán tan pronto como nuestra URL se publique en algunas de las páginas que ya tienen indexadas.
No hace ni falta que nuestra URL se publique en formato enlace. Con que aparezca en el contenido de una página indexada las arañas la encontrarán y la pondrán en la cola de URLs a visitar e indexar.
Cuantos más enlaces y referencias externas tengamos apuntando a nuestra página, más posibilidades tendremos de una indexación rápida y completa. Sobre todo si nuestro site tiene decenas de miles de páginas, necesitaremos una buena cantidad de enlaces para justificar el “esfuerzo” que tendrán que hacer las arañas para visitarlas e indexarlas todas.
Por ello, a día de hoy con generar algunos enlaces a nuestra web desde un perfil de Google+, en Twitter, en grupos de LinkedIn o desde algún blog relacionado temáticamente será suficiente para indexarnos.
Importante mencionar que los robots o arañas siempre ha tenido problemas con:
- Ejecutar JavaScript completo: durante los últimos años han incorporado capacidades nuevas de ejecución de JavaScript a los robots pero si, por ejemplo, nuestro menú es un desplegable con múltiples opciones realizado en JavaScript (ej.: el típico selector de provincia o de país) el robot tendrá problemas serios para indexar las páginas internas de nuestra web a las que apunten esas opciones. Por ello, por regla general, debemos evitar el JavaScript para mostrar contenido o crear elementos de navegación o crear rutas “alternativas” a través de enlaces en HTML plano.
- Entender archivos Flash: en contra de lo que muchos piensan Google y el resto de buscadores SÍ indexan Flash. El problema que encuentran es que toda la página web suele estar contenida en un único archivo flash (.flv), que a su vez reside en una única URL. Una vez que se ejecuta el Flash el usuario puede moverse entre secciones, etc…No obstante, el buscador no tiene la capacidad de entender qué parte del código flash se corresponde a qué sección y, al haber sólo 1 URL en su índice, las posibilidades de posicionamiento de esa web en Flash se verán reducidas de forma muy significativa. Esa URL si aparecerá pero no se posicionará apenas por ninguna palabra.
El trabajo de estas arañas suele desarrollarse en ciclos de 6-8 semanas en las que recorrerán todo las partes de Internet a las que puedan llegar (ej.: contenido protegido por usuario y contraseña está fuera de su alcance) e indexarán tantas páginas como se encuentren creando el índice del buscador.
Este ciclo de indexación, en el caso de Google, le lleva a recorrer e indexar aproximadamente un 70% de lo que hay disponible en Internet (que se estima en unos cuantos miles de millones de documentos).
Una vez que se ha indexado la URL, el motor de búsqueda valora la relevancia de cada página dentro de su índice. Esto es, para qué palabras es relevante cada URL encontrada y cómo se compara con el resto de URLs que contienen esas palabras.
Usando algoritmos complejos que miden y comparan alrededor de 200 factores, consiguen establecer sobre qué trata una página y en qué búsquedas debería aparecer. Estos cálculos serán almacenados como parte de una base de datos en ese servidor.
Las URLs contenidas en esta base de datos o índice del buscador serán las que se muestren cuando alguien realiza una búsqueda en los motores de búsquedas, ordenadas por relevancia en base a lo que decida el algoritmo.
El trabajo de los especialistas en SEO es realizar ingeniería inversa para determinar cómo trabaja el Algoritmo de Google, qué factores son importantes y así entender lo que necesitamos hacer para mejorar el posicionamiento de un sitio en específico aunque eso merece un post nuevo.